.jpeg)
Louis Graffeuil
14/5/2024
•
10 min read


Plusieurs outils sont disponibles pour extraire des informations d’un document. L’un des outils les plus performants actuellement est développé par Anthropic et se nomme Claude. L’interface est similaire à ChatGPT.
C’est cet outil que nous allons utiliser pour nos cas d’usage. Nous allons distinguer :
Un résumé d’un fichier volumineux et / ou des précisions sur certaines informations précises du document (donnée, éléments positifs ou négatifs du rapport, …).
Prompt basique : Je souhaite que tu me résumes les informations uniquement liées à l'intelligence artificielle dans ce rapport. Je souhaite une réponse concise sous forme de bullets points, chiffrée si possible.
Rapport de davos début 2024 sur les risques.
Le document est en anglais et fait une centaine de pages.

Analyse sur plusieurs documents d’un produit financier sur une durée de plus d’1 an (ajout de 5 documents). L’objectif est de connaitre l’évolution du produit financier sur la durée

Sur ces demandes basiques, il est aussi pratique de modifier le prompt pour demander une extraction de certaines données sous un format spécifique (csv, json, etc) et l’exploiter plus facilement ailleurs.
Dans les exemples, j’ai utilisé des formats PDF pour l’analyse d’informations, mais on peut extraire les informations de documents en format :
Pour les besoins récurrents, on va optimiser le prompt pour que le modèle soit plus performant.
Les prompts peuvent sembler anodins, mais leur optimisation permet d’optimiser drastiquement la performance. (voir cette étude réalisant des comparaisons sur les résultats en fonction des prompts)
J’ai une liste de documents sur google drive, je souhaite extraire certaines informations chiffrés dans ces documents. Ils sont publiés tous les trimestres, je vais donc sortir de l’interface pour créer un process entier d’analyse de données.
Malheureusement, Claude et GPT ne permettent pas d’analyser un document depuis l’API. Je me suis pas mal cassé la tête sur le sujet pour trouver une solution et ça se passe sur Google Apps Script. (GAS)
Voici les étapes :
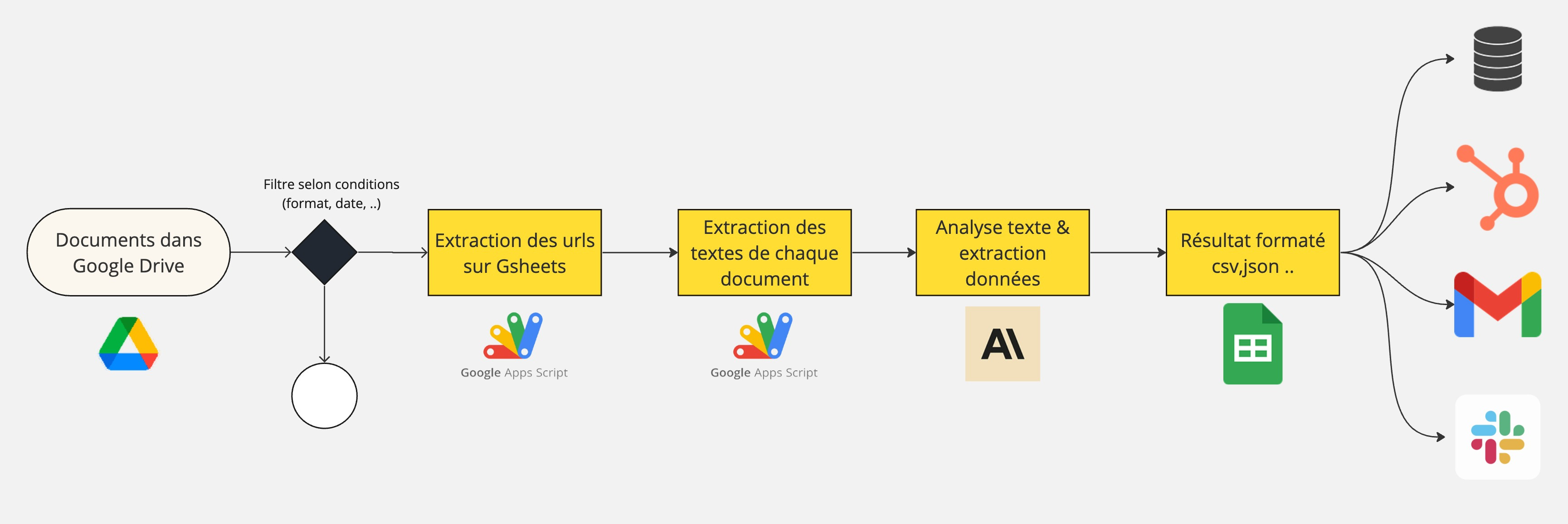
Après avoir ajouté mes documents dans un dossier Google Drive, le process me génère des informations précises de tous les documents.
Sur cette solution, l’IA générative est utilisée uniquement à la 3ᵉ étape car l’API n’est pas disponible pour traiter directement les documents. Le résultat obtenu par GAS n’est pas optimal et a ses limites, en lien avec la qualité de l’analyse du document fait par le script.
Petit aperçu du résultat sur une feuille gsheets. Dans cet exemple, je demande uniquement la valeur numérique comme résultat pour compléter une base de données.
J’ai une série de facture / notes de frais. J’ai ajouté l’ensemble des documents dans un google drive depuis mon téléphone. Je souhaite extraire les informations suivantes :
On utilise exactement la même procédure, le prompt est par contre modifié pour être plus résilient.
Tu es office manager, tu dois analyser rigoureusement les informations d’un texte et en extraire certaines. Les informations proviennent d’une analyse OCR, il est possible que certains éléments soient incorrects.
Pour éviter toute erreur d’analyse, tu devras :
- faire plusieurs analyses de texte pour confirmer la cohérence des informations. S’il y a une incohérence dans les informations, tu afficheras la valeur ‘Erreur de lecture’. Par exemple le total de la facture doit correspondre à la somme des montants.
- si tu ne nous trouves pas une information dans le texte après plusieurs analyses, tu afficheras la valeur ‘Erreur de lecture’. Ne donne pas de résultat si l'information n'est pas explicitement mentionnée dans le texte.
- si le contenu ne semble pas être une facture, une note de frais, un ticket, ou tout autre document ne correspondant pas à une dépense au sein d’une entreprise, tu afficheras la valeur ‘Erreur de lecture’.
Voici le texte : [INSERTION DU TEXTE]
Voici les informations à extraire avec uniquement les valeurs sans texte supplémentaire :
- date du document au format JJ/MM/AAAA
- nom de l’établissement
- montant total en ajoutant le symbole de la devise monétaire. Par exemple '€' pour l'euro. La virgule est utilisé pour afficher les décimales plutôt qu'un point.
Pas de texte supplémentaire en dehors du résultat au format CSV séparé par des points virgules
Un aperçu de ce que cela donne sur GSheets.
Il y a pleins de cas possibles sur l’extraction de données à partir de documents, n’hésitez à commenter si vous en avez d’autres ou besoins d’aide.
Vous pouvez retrouver les scripts Google Apps sur ce google docs si besoin.
Pour un besoin ponctuel, vous pouvez utiliser poe.com, comme interface qui permet d’utiliser des modèles différents dont Claude 3 gratuitement.
Pour l’utilisation d’une clé API et un besoin plus important, vous pouvez utiliser claude directement sur Anthropic et créer votre clé API depuis le dashboard, l’abonnement est à partir de 20€/mois. (Le service par API n’est pas accessible en France, il faudra utiliser un VPN).
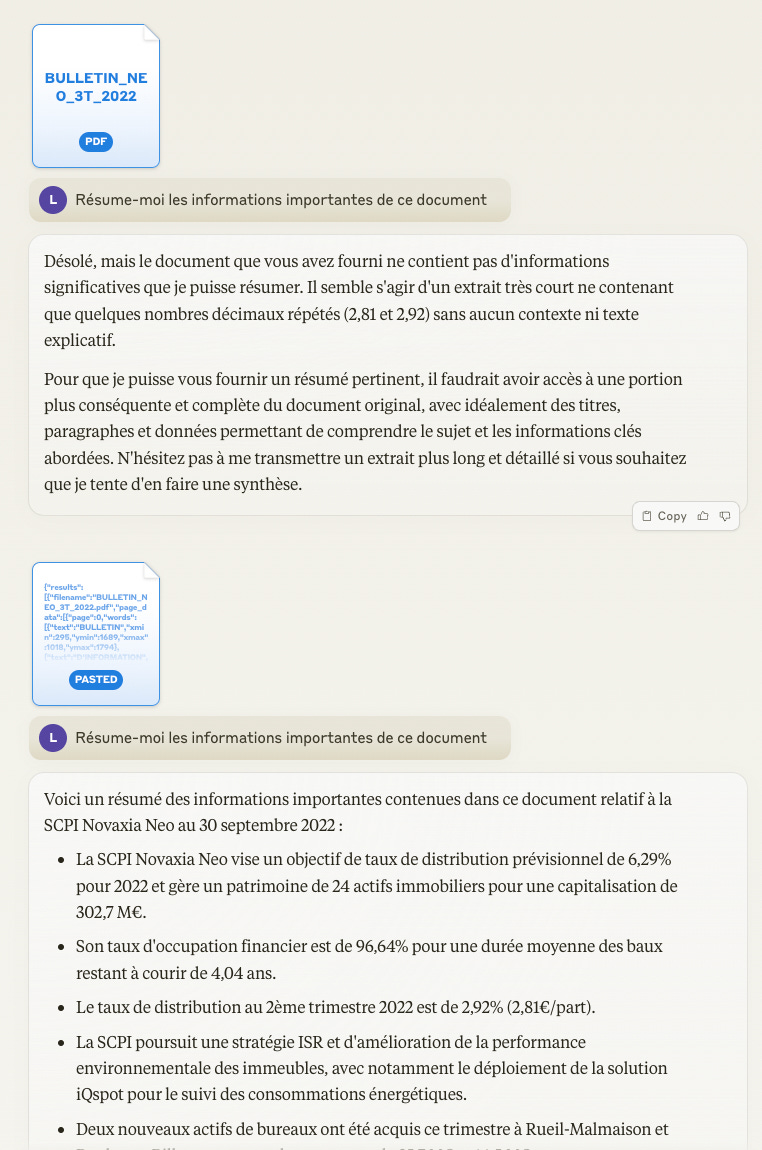
Claude-3 est l’outil le plus avancé du marché sur l’analyse de documents. Il est trés performant depuis l’interface utilisateur et la pertinence du résultat dépendra fortement du prompt envoyé. Cela reste un indispensable pour une personne manipulant des documents (même occasionnellement) étant donné le temps que cela peut faire gagner !
En ce qui concerne une utilisation plus “industrialisé” de l’outil, pour l’instant c’est compliqué pour plusieurs raisons :
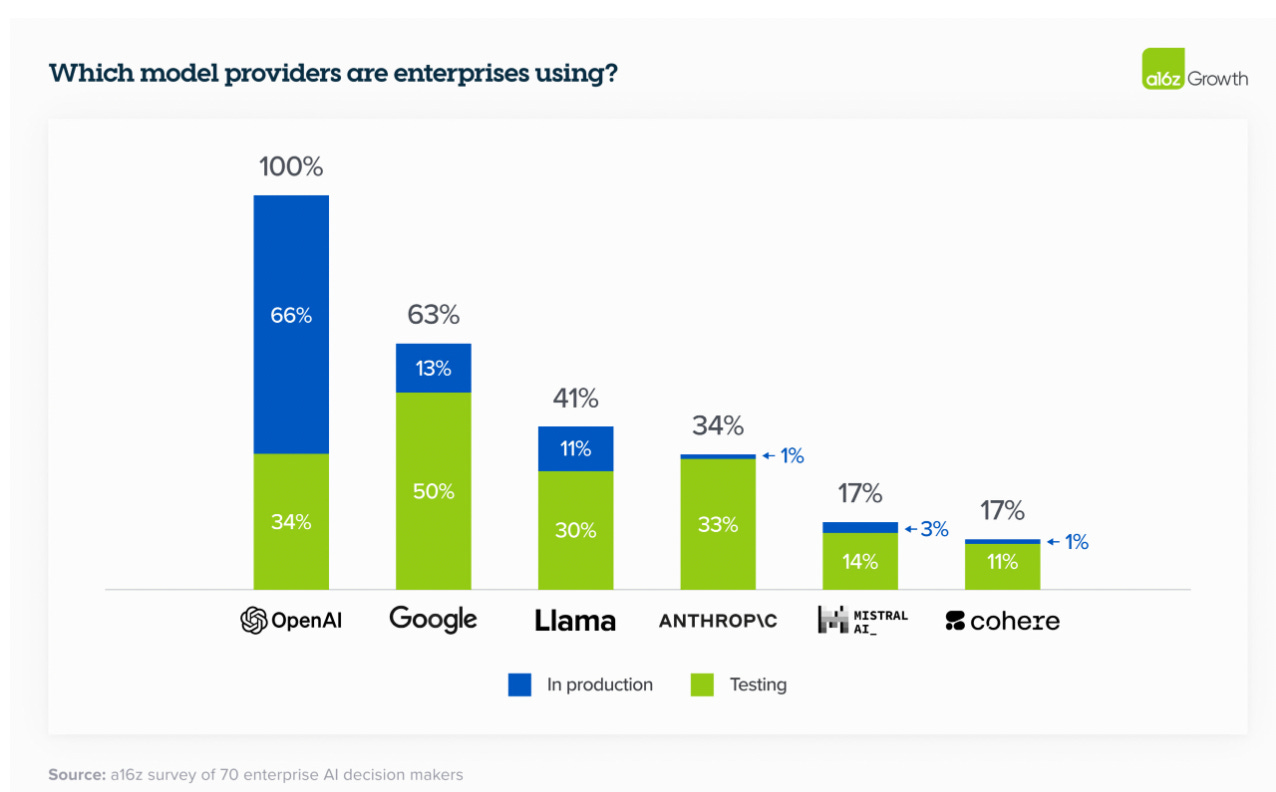
Ce n’est pas étonnant que l’outil est encore très peu utilisé dans des process complets en production comme le révélait une étude de A16Z.